Introduction
I’ve been working on a time-series analysis project where the data are stored as structures in massive binary files. Importing the files into a database would cause a performance hit with no value added, so dealing with the files in their original binary format is the best option. My initial assumption was that throughput would be limited by disk speed, but I found that my first implementation resulted in 100% CPU utilization on my research box. It was obviously time to optimize.
While there is a wealth of information available on the innumerable ways of reading files with C#, there is virtually no discussion about the performance implications of various design decisions. Hopefully, this article will allow the reader to improve the performance of binary file reading in their application and will shed some light on some of the undocumented performance traps hidden in the System.IO classes.
Is there Data?
It may seem silly to have a section on checking for the end of a file (EOF), but there are a plethora of methods employed by programmers, and improperly checking for the EOF can absolutely cripple performance and introduce mysterious errors and exceptions to your application.
BinaryReader.PeekChar Method
If you are using this method in any application, god save you. Based on its frequent appearance in .NET newsgroups, this method is widely used, but I’m not sure why it even exists. According to Microsoft, the BinaryReader.PeekChar method “Returns the next available character and does not advance the byte or character position.” The return value is an int containing “The next available character, or -1 if no more characters are available or the stream does not support seeking.” Gee, that sounds awfully useful in determining if we’re at the end of the stream.
The BinaryReader class is used for reading binary files which are broken into bytes not chars, so why peek at the next char rather than byte? I could understand if there was an issue implementing a common interface, but the TextReader derived classes just use Peek. Why doesn’t the BinaryReader include a plain old Peek method that returns the next byte as an int? By now, you’re probably wondering why I’m ranting so much about this. Who cares? So, you get the next byte for free? Well, something entirely unnatural happens somewhere in the bowels of this method that periodically results in a “Conversion Buffer Overflow” exception. As the result of some dark voodoo process, certain two byte combinations in your binary file can not be converted into an appropriate return value by the method. I have no idea why certain byte combinations have been deigned toxic to PeekChar, but prepare for freaky results if you use it.

Stream.Position >= Stream.Length
This test is pretty straightforward. If your current position is greater than or equal to the length of the stream, you’re going to be pretty hard-pressed to read any additional data. As it turns out, this statement is a massive performance bottleneck.
After finishing the initial build of my application, it was time for some optimization. I downloaded the ANTS Profiler Demo from Red Gate Software, and was shocked to find that over half the execution time of my program was being spent in the EOF method of my data reader. Without the profiler results, I never would have imagined that this innocuous looking line of code was cutting the performance of my application into half. After all, I opened the FileStream using the FileShare.Read option, so there was no danger of the file’s length changing, but it appears as though the position and file length are not cached by the class, so every call to Position or Length results in another file system query. In my benchmarking, I’ve found that calling both Position and Length takes twice as long as calling one or the other.
_position >= _length (Cache it yourself)
It’s sad, but true. This is the fastest method by a long shot. Get the length of your FileStream once when you open it, and don’t forget to advance your position counter every time you read. Maybe Microsoft will fix this performance trap someday, but until then, don’t forget to cache the file length and position yourself!
Read It!
Now that we know there’s data, we have to read it into our data structures. I’ve included three different approaches, with varying merits. I did not include the unsafe approach of casting a byte array of freshly read data into a structure because I prefer to avoid unsafe code if at all possible.
FileStream.Read with PtrToStructure
Logically, I assumed that the fastest way to read in a structure would be the functional equivalent of C++’s basic_istream::read method. There are plenty of articles and newsgroup posts about using the Marshal class in order to torture raw bits into a struct. The cleanest implementation I’ve found is this:
public static TestStruct FromFileStream(FileStream fs)
{
//Create Buffer
byte[] buff = new byte[Marshal.SizeOf(typeof(TestStruct))];
int amt = 0;
//Loop until we've read enough bytes (usually once)
while(amt < buff.Length)
amt += fs.Read(buff, amt, buff.Length-amt); //Read bytes
//Make sure that the Garbage Collector doesn't move our buffer
GCHandle handle = GCHandle.Alloc(buff, GCHandleType.Pinned);
//Marshal the bytes
TestStruct s =
(TestStruct)Marshal.PtrToStructure(handle.AddrOfPinnedObject(),
typeof(TestStruct));
handle.Free();//Give control of the buffer back to the GC
return s
}BinaryReader.ReadBytes with PtrToStructure
This approach is functionally almost identical to the FileStream.Read approach, but I provided it as a more apples-to-apples comparison to the other BinaryReader approach. The code is as follows:
public static TestStruct FromBinaryReaderBlock(BinaryReader br)
{
//Read byte array
byte[] buff = br.ReadBytes(Marshal.SizeOf(typeof(TestStruct)));
//Make sure that the Garbage Collector doesn't move our buffer
GCHandle handle = GCHandle.Alloc(buff, GCHandleType.Pinned);
//Marshal the bytes
TestStruct s =
(TestStruct)Marshal.PtrToStructure(handle.AddrOfPinnedObject(),
typeof(TestStruct));
handle.Free();//Give control of the buffer back to the GC
return s;
}BinaryReader with individual Read calls for structure fields
I assumed that this would be the slowest method for filling my data structures --it was certainly the least sexy approach. Here’s the relevant sample code:
public static TestStruct FromBinaryReaderField(BinaryReader br)
{
TestStruct s = new TestStruct();//New struct
s.longField = br.ReadInt64();//Fill the first field
s.byteField = br.ReadByte();//Fill the second field
s.byteArrayField = br.ReadBytes(16);//...
s.floatField = br.ReadSingle();//...
return s;
}Results
As I’ve already foreshadowed, my assumptions about the performance of various read techniques was entirely wrong for my data structures. Using the BinaryReader to populate the individual fields of my structures was more than twice as fast as the other methods. These results are highly sensitive to the number of fields in your structure. If you are concerned about performance, I recommend testing both approaches. I found that, at about 40 fields, the results for the three approaches were almost equivalent, and beyond that, the block reading approaches gained an upper hand.
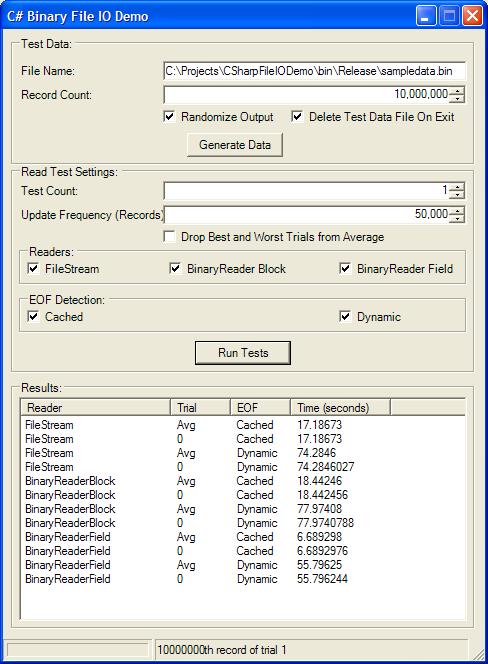
Using the Test App
I’ve thrown together a quick benchmarking application with simplified reading classes to demonstrate the techniques outlined so far. It has facilities to generate sample data and benchmark the three reading approaches with dynamic and cached EOF sensing.
Generating Test Data
By default, test data is created in the same directory as the executable with the filename “sampledata.bin”. The number of records to be created can be varied. Ten million records will take up a little bit more than 276 MB, so make sure you have enough disk space to accommodate the data. The ‘Randomize Output’ checkbox determines whether each record will be created using random data to thwart NTFS’s disk compression. Click the ‘Generate Data’ button to build the file.
Benchmarking
Benchmarking results are more reliable when averaged over many trials. Adjust the number of trials for each test scenario using the ‘Test Count’ box. ‘Update Frequency’ can be used to adjust how frequently the status bar will inform you of progress. Designate an update frequency greater than the number of records to avoid including status bar updates in your benchmark results. The ‘Drop Best and Worst Trials from Average’ check box will omit the longest and shortest trial from the average entry --they will still be listed in the ‘Results’ ListView. Select the readers to be tested using the checkboxes –‘BinaryReader Block’ corresponds to the PtrToStructure approach. Select the ‘EOF detection’ methods to test --'Dynamic’ uses Length and Position properties each time EOF is called. Click ‘Run Tests’ to generate results.
Miscellaneous Findings
StructLayoutAttribute
If you’re working with reading pre-defined binary files, you will become very familiar with the StructLayoutAttribute. This attribute allows you to tell the compiler specifically how to layout a struct in memory using the LayoutKind and Pack parameters. Marshaling a byte array into a structure where the memory layout differs from its layout on disk will result in corrupted data. Make sure they match.
Warning! Depending on the way a structure is saved, you may need to read and discard empty packing bytes between reading fields when using the BinaryReader.
MarshalAsAttribute
Be sure to use the MarshalAsAttribute for all fixed width arrays in your structure.Structures with variable length arrays cannot be marshaled to or from pointers.
Writing Data
Writing binary data can be accomplished in the same ways as reading. I imagine that the performance considerations are very similar as well. So, writing out the fields of a structure using the BinaryWriter is probably optimal for small structures. Larger structures can be marshaled into byte arrays using this pattern:
public byte[] ToByteArray()
{
byte[] buff = new byte[Marshal.SizeOf(typeof(TestStruct))];//Create Buffer
GCHandle handle = GCHandle.Alloc(buff, GCHandleType.Pinned);//Hands off GC
//Marshal the structure
Marshal.StructureToPtr(this, handle.AddrOfPinnedObject(), false);
handle.Free();
return buff;
}Marshal.SizeOf
Even small changes to a method can yield significant boost to performance when the method is called millions or billions of times during the execution of a program. Apparently, Marshal.SizeOf is evaluated at runtime even when there is a call to typeof as the parameter. I shaved several minutes off of my application’s execution time by creating a class with a static Size property to use in place of Marshal.SizeOf. Since the return value is calculated every time the application is started, the dangers of using a constant for size are avoided.
internal sealed class TSSize
{
public static int _size;
static TSSize()
{
_size = Marshal.SizeOf(typeof(TestStruct));
}
public static int Size
{
get
{
return _size;
}
}
}