1.制作股票代号-股票名称同义词词典,并添加入路径(同时需要将股票名称添加进拓展词典)
首先,通过Python,我们将收集股票名称和股票代码来制作同义词词典。
股票数据来源来自于东方财富网。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import requests from bs4 import BeautifulSoup #用两个列表分别存储上证和深证各支股票的信息 sh = [] sz = [] with requests.Session() as s: html = s.get(r'http://quote.eastmoney.com/stocklist.html') soup = BeautifulSoup(html.content, 'lxml') sh_stocks =soup.find_all('ul')[7] for i in sh_stocks.find_all('li'): sh.append(i.a.text) sz_stocks =soup.find_all('ul')[8] for i in sz_stocks.find_all('li'): sz.append(i.a.text) |
输出的本文结果为如下格式
1 2 3 4 5 6 7 8 9 10 11 | ... 501001,财通精选 501002,能源互联 501003,上海改革 501005,精准医疗 ... 510190,龙头etf 510210,综指etf 510220,中小etf 510230,金融etf ... |

首先,由于分词ik不能识别股票名称(不能正确分词),即使添加了同义词词典也无法检索到,所以需要在拓展词库中添加全部股票名称。
其中,由于用户输入一般是忽略大小写的,为了方便用户能够输入大小写都能匹配到股票信息,我们将拓展词典、同义词词典的股票名称信息都更改为小写,这样无论用户输入大写还是小写都能匹配到股票。
暂时没有找到关闭 filter 号的方法,所以搜索不了 stXX股票
有没有可能去除st等标记,因标记是在原股票名称前添加,不改变原股票名称
2.学习使用html_strip filter
html strip filter 代码如下:
1 2 3 4 5 6 | "char_filter": { "my_html": { "type": "html_strip", "escaped_tags": [] } } |
其中escaped_tags字段表示该列表之中的标签不用去除
3.创建索引,并设置IK为Tokenizer,Filter包括同义词和html_strip
完整设置和mapping如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | { "settings": { "index" : { "analysis" : { "analyzer" : { "my_analyzer" : { "tokenizer" : "my_ik", "filter" : ["my_stop","synonym"], "char_filter": ["my_html"] } }, "char_filter": { "my_html": { "type": "html_strip", "escaped_tags": [] } }, "filter" : { "synonym" : { "type" : "synonym", "synonyms_path" : "synonym.txt" }, "my_stop":{ "type":"stop", "stopwords":"_none_" } }, "tokenizer":{ "my_ik":{ "type":"ik_max_word", "enable_lowercase":true } } } } }, "mappings":{ "news":{ //类型名,这里为news "properties": { "title": { "type": "text", "analyzer": "my_analyzer" }, "keywords":{ "type": "text", "analyzer": "my_analyzer" }, "content":{ "type": "text", "analyzer": "my_analyzer" } } } } } |
还需要完善:
- 对于不需要和不希望加入搜索的字段进行not_analyze设置
- 设置日期字段的数值类型date
4.对已有数据进行reindex(约34w数据)
之前进行reindex速度明显比这次高,原因是上次没有使用analyzer。
此次reindex 34w数据共用时793秒,每1秒操作428个文档。
如无analyzer,则每一秒操作1581个文档。
5.使用function_score进行filter检索,发布时间越靠前的得分越高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | GET test/news/_search?search_type=dfs_query_then_fetch { "_source": ["title","publishdate"], "query": { "function_score": { "query":{ "match": { "title": "600340" } } , "functions": [ { "exp": { "publishdate" : { "origin": "now", "offset": "1h", "scale" : "30d", "decay": 0.2 } }, "weight": 200 } ], "boost_mode": "sum" } } } |
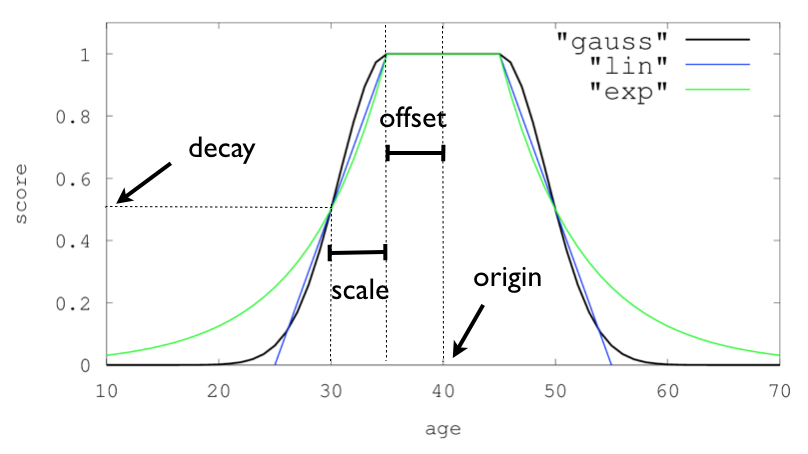
其中使用的是function score query 的 decayfunction(衰减函数)。
各参数设置如图:
stocksight
stocksight是一个开源的股票市场分析软件,它使用Elasticsearch存储Twitter和股票的新闻标题数据。stocksight分析作者所写内容的情感,并对文本进行情绪分析,以确定作者对股票的“感觉”。
https://www.5axxw.com/wiki/content/ecshb2
1.自己通过echarts之类的可视化框架做可视化也是个不错的选择,不过前期成本太大。
2. pandas+matplotlib已经足以应付大部分需求了,可是交互感太弱,所以借助一个可视化应用是很有必要的.
3.选择的是kibana, 它的竞品有Grafana.
Kibana 是为 Elasticsearch设计的开源分析和可视化平台.
https://zhuanlan.zhihu.com/p/76758435
Useful links
数据情况:
全部为股票及指数的分钟K线数据。
从mongodb导入数据到elastic search