OS
Table of Contents
elasticsearch 7.4.2
Config files location
Configuration file directory (which needs to include elasticsearch.yml, jvm.options, and log4j2.properties files); defaults to /etc/elasticsearch
/etc/elasticsearch/elasticsearch.yml for configuring Elasticsearch
/etc/elasticsearch/jvm.options for configuring Elasticsearch JVM settings
/etc/elasticsearch/log4j2.properties for configuring Elasticsearch loggingfor more information See
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/settings.html
查看进程内存占用情况
使用top命名,可以显示进程列表,
然后键盘按下M键,可以按照内存降序,结果如下
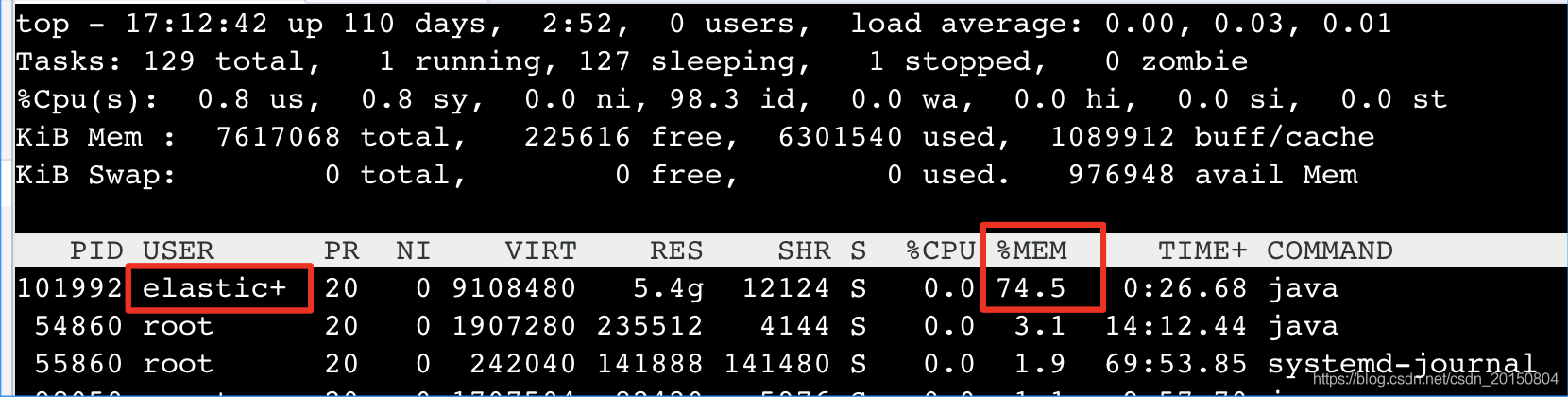
elastic+就是es的进程.设置的是6g,物理总内存为8g,所以光es进程就占用了75%(java 堆内存).
另外:es内核使用lucene,一个内存消耗大户 非堆内存 (off-heap:Lucene。lucene本身是单独占用内存的,并且占用的还不少。lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问。官方建议设置es内存,大小为物理内存的一半留给ES(JVM heap ),剩下的一半留给lucene。
Lucene的设计目的是把底层OS里的数据缓存到内存中。Lucene的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。
Lucene的性能取决于和OS的交互,如果你把所有的内存都分配给Elasticsearch,不留一点给Lucene,那你的全文检索性能会很差.
堆内存越小,Elasticsearch(更快的 GC)和 Lucene(更多的内存用于缓存)的性能越好。
最后标准的建议是把50%的内存给elasticsearch,剩下的50%,Lucene会很快吞噬剩下的这部分内存用于文件缓存。
# top
top - 08:41:09 up 4:26, 4 users, load average: 0.00, 0.05, 0.10
Tasks: 120 total, 1 running, 85 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 4039176 total, 109048 free, 2700852 used, 1229276 buff/cache
KiB Swap: 969964 total, 870880 free, 99084 used. 1050176 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
803 root 10 -10 141324 10820 5052 S 2.0 0.3 4:04.45 AliYunDun
544 mongodb 20 0 1748124 181248 10116 S 0.7 4.5 1:21.24 mongod
8 root 20 0 0 0 0 I 0.3 0.0 0:24.32 rcu_sched
472 www-data 20 0 12.067g 209300 22816 S 0.3 5.2 0:26.29 dotnet
1657 root 20 0 805852 7144 3164 S 0.3 0.2 0:17.14 aliyun-service
31294 elastic+ 20 0 3752080 1.249g 15544 S 0.3 32.4 0:40.57 java
查看进程内存设置情况
ps -ef | grep javaoutput
elastic+ 1510 1 0 Nov12 ? 00:06:06 /usr/share/elasticsearch/jdk/bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dio.netty.allocator.numDirectArenas=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.io.tmpdir=/tmp/elasticsearch-13273292652441864852 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/lib/elasticsearch -XX:ErrorFile=/var/log/elasticsearch/hs_err_pid%p.log -Xlog:gc*,gc+age=trace,safepoint:file=/var/log/elasticsearch/gc.log:utctime,pid,tags:filecount=32,filesize=64m -Djava.locale.providers=COMPAT -Dio.netty.allocator.type=unpooled -XX:MaxDirectMemorySize=536870912 -Des.path.home=/usr/share/elasticsearch -Des.path.conf=/etc/elasticsearch -Des.distribution.flavor=default -Des.distribution.type=deb -Des.bundled_jdk=true -cp /usr/share/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -p /var/run/elasticsearch/elasticsearch.pid --quiet
root 27966 28778 0 18:39 pts/1 00:00:00 grep --color=auto javaStep 1:给运行es的用户memlock锁内存权限
设置之后并不会生效, 因为elasticsearch没有权限去锁定内存, 需要更改配置文件/etc/security/limits.conf
/etc/security/limits.conf
* soft nofile 65535 #这个是默认的
* hard nofile 65535 #这个也是默认的
elastic - memlock unlimited #给es权限去锁定内存
Elasticsearch堆内存
Elasticsearch默认堆内存为1 GB,对于实际应用,显然不够,不建议使用默认配置。
有几种方式修改 Elasticsearch 的堆内存。
1.指定 ES_HEAP_SIZE 环境变量。
服务进程在启动时候会读取这个变量,并相应的设置堆的大小。 比如,你可以用下面的命令设置它:
export ES_HEAP_SIZE=10g2.通过命令行参数的形式,在程序启动的时候把内存大小传递给它:
./bin/elasticsearch -Xmx10g -Xms10g3.修改jvm.options文件
./bin/elasticsearch -Xmx10g -Xms10g
常用的配置在两个文件里,分别是 elasticsearch.yml 和 jvm.options(配置内存)
/etc/elasticsearch/elasticsearch.yml
bootstrap.memory_lock: true
#设置为true锁住内存,当服务混合部署了多个组件及服务时,应开启此操作,允许es占用足够多的内存。
正确设置内存的方式:修改jvm.options文件
You should always set the min and max JVM heap.
/etc/elasticsearch/jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m
-Xmx512mrestart service
sudo systemctl restart elasticsearch.serviceoutput
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6088 elastic+ 20 0 3232548 791392 29384 S 1.0 19.6 0:29.04 java
516 mongodb 20 0 2678696 1.014g 9212 S 0.7 26.3 16:20.44 mongod
初始堆和最大堆 设置相等 原因 :
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆的大小。
for more information See https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
/etc/elasticsearch/elasticsearch.yml
JVM 堆 是有限资源的,应该被合理利用。 限制 fielddata 对堆使用的影响有多套机制。
indices.fielddata.cache.size 控制为 fielddata 分配的堆空间大小。 当你发起一个查询,分析字符串的聚合将会被加载到 fielddata,如果这些字符串之前没有被加载过。如果结果中 fielddata 大小超过了指定 大小 ,其他的值将会被回收从而获得空间。
默认情况下,设置都是 unbounded ,Elasticsearch 永远都不会从 fielddata 中回收数据。
这个默认设置是刻意选择的:fielddata 不是临时缓存。它是驻留内存里的数据结构,必须可以快速执行访问,而且构建它的代价十分高昂。如果每个请求都重载数据,性能会十分糟糕。
设想我们正在对日志进行索引,每天使用一个新的索引。通常我们只对过去一两天的数据感兴趣,尽管我们会保留老的索引,但我们很少需要查询它们。不过如果采用默认设置,旧索引的 fielddata 永远不会从缓存中回收! fieldata 会保持增长直到 fielddata 发生断熔,这样我们就无法载入更多的 fielddata。
参数 indices.fielddata.cache.size 控制有多少堆内存是分配给fielddata
为了防止发生这样的事情,可以通过在 config/elasticsearch.yml 文件中增加配置为 fielddata 设置一个上限:
indices.fielddata.cache.size: 20%有了这个设置,最久未使用(LRU)的 fielddata 会被回收为新数据腾出空间。
断路器
indices.breaker.fielddata.limit
fielddata 断路器默认设置堆的 60% 作为 fielddata 大小的上限。
indices.fielddata.cache.size
缓存回收大小,无默认值, 有了这个设置,最久未使用(LRU)的 fielddata 会被回收为新数据腾出空间
禁止swap,一旦允许内存与磁盘的交换,会引起致命的性能问题。 通过: 在elasticsearch.yml 中 bootstrap.memory_lock: true, 以保持JVM锁定内存,保证ES的性能。
# 禁用swapping,开启服务器虚拟内存交换功能会对es产生致命的打击
# /etc/elasticsearch/elasticsearch.yml
#
# ElasticSearch配置
#
cluster.name: forNe
# Node名称可以用来做路由
node.name: ne-01
node.datacenter: center
# Force all memory to be locked, forcing the JVM to never swap
bootstrap.mlockall: true
##线程池设置 ##
# 搜索池
threadpool.search.type: fixed
threadpool.search.size: 20
threadpool.search.queue_size: 100
# Bulk池
threadpool.bulk.type: fixed
threadpool.bulk.size: 60
threadpool.bulk.queue_size: 300
# 索引池
threadpool.index.type: fixed
threadpool.index.size: 20
threadpool.index.queue_size: 100
# Indices settings
indices.memory.index_buffer_size: 20%
indices.memory.min_shard_index_buffer_size: 12mb
indices.memory.min_index_buffer_size: 96mb
# Cache Sizes
indices.fielddata.cache.size: 15%
indices.fielddata.cache.expire: 6h
indices.cache.filter.size: 15%
indices.cache.filter.expire: 6h
# Indexing Settings for Writes
index.refresh_interval: 5s
index.translog.flush_threshold_ops: 50000操作系统环境配置
禁用swapping
如果内存交换到磁盘上,一个100微秒的操作可能变成10毫秒,再想想那么多10微秒的操作时延累加起来。不难看出swapping对于性能是多么可怕。
最好的办法就是在你的操作系统中完全禁用swapping。这样可以暂时禁用:
sudo swapoff -a
如果完全禁用swap,对你来说是不可行的。你可以降低swappiness 的值,这个值决定操作系统交换内存的频率。这可以预防正常情况下发生交换。但仍允许os在紧急情况下发生交换。
对于大部分Linux操作系统,可以在sysctl 中这样配置:
vm.swappiness = 1
备注:swappiness设置为1比设置为0要好,因为在一些内核版本,swappness=0会引发OOM(内存溢出)
简单地说这个参数定义了系统对swap的使用倾向,默认值为60,值越大表示越倾向于使用swap。可以设为0,这样做并不会禁止对swap的使用,只是最大限度地降低了使用swap的可能性。
通过sysctl -q vm.swappiness可以查看参数的当前设置。
修改参数的方法是修改/etc/sysctl.conf文件,加入vm.swappiness=xxx,并重起系统。这个操作相当于是修改虚拟系统中的/proc/sys/vm/swappiness文件,将值改为XXX数值。
/etc/sysctl.conf
vm.swappiness = 60如果不想重起,可以通过sysctl -p动态加载/etc/sysctl.conf文件,但建议这样做之前先清空swap。
# 禁用swapping,开启服务器虚拟内存交换功能会对es产生致命的打击
Virtual memory
Elasticsearch uses a mmapfs directory by default to store its indices. The default operating system limits on mmap counts is likely to be too low, which may result in out of memory exceptions.
On Linux, you can increase the limits by running the following command as root:
sysctl -w vm.max_map_count=262144To set this value permanently, update the vm.max_map_count setting in /etc/sysctl.conf
在/etc/sysctl.conf文件中找到该参数vm.max_map_count,修改 655300 为 262144。
执行sysctl -p 使其生效,不然启动时会报值太小
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/settings.html
elasticsearch 8.15.3