目前已知的并行计算的实现,有如下分类:
1.在多个物理CPU或单个物理CPU多核心上进行计算
2.在GPU上进行计算
为了能够并行计算,各大公司陆续创建了自己的方案,从而形成了多套方案:
1.库函数方案,从C,到C++到C++26
2.第三方软件公司开发的库,如:OpenMP
3.第三方硬件公司开发的库,如:N卡,Intel
4.专门为操作系统开发的库,如:Pthread, CreateThread(Windows)
Table of Contents
基本介绍 - 并行编程实现可选方案
并行编程实现可选方案(硬件、软件[库函数方案、第三方软件公司开发的库,如:OpenMP])
C++标准并没有提供对多进程并发的原生支持,所以C++的多进程并发要靠其他API——这需要依赖相关平台。
C++11 标准提供了一个新的线程库,内容包括了管理线程、保护共享数据、线程间的同步操作、低级原子操作等各种类。标准极大地提高了程序的可移植性,以前的多线程依赖于具体的平台,而现在有了统一的接口进行实现。
目前已知的并行计算的实现,有如下分类:
1.在多个物理CPU或单个物理CPU多核心上进行计算
2.在GPU上进行计算
为了能够并行计算,各大公司陆续创建了自己的方案,从而形成了多套方案:
1.库函数方案,从C,到C++到C++26
2.第三方软件公司开发的库,如:OpenMP
3.第三方硬件公司开发的库,如:N卡,Intel
4.专门为操作系统开发的库,如:Pthread, CreateThread(Windows)
并行的分类
并行
├── 1️⃣ 数据并行(Data Parallel)
├── 2️⃣ 任务并行(Task Parallel)
├── 3️⃣ 流水线并行(Pipeline Parallel)
├── 4️⃣ 空间并行(Domain / Spatial Parallel)
├── 5️⃣ 指令级并行(ILP / SIMD)
数据并行(Data Parallel)
for (int i = 0; i < nSize; i++) //按股票代码循环 {计算} 分别用c++ 和c#实现多核cpu并行计算,比较性能按股票代码循环计算(nSize 通常很大),计算是 CPU 密集型(无 IO),这是**典型的数据并行(Data Parallel)**问题,非常适合多核。
VS C++ 可用的多核cpu并行方案
1.OpenMP(/openmp)
#pragma omp parallel for
for (int i = 0; i < N; i++) {
a[i] += b[i];
}
2.C++17/20/26 标准库
std::thread
std::async
std::execution::parC++ standard library
1.C++17/20/26 标准库库函数方案 - C/C++版本更迭历程
C语言版本更迭
| 年份 | C标准 | 通用名 | 别名 | 标准编译选项 | GNU扩展选项 |
|---|---|---|---|---|---|
| 1972 | Birth C | - | - | - | - |
| 1978 | K&R C | - | - | - | - |
| 1989-1990 | X3.159-1989, ISO/IEC 9899:1990 | C89 | C90, ANSI C, ISO C | -ansi, -std=c90, -std=iso9899:1990 | -std=gnu90 |
| 1995 | ISO/IEC 9899/AMD1:1995 | AMD1 | C94, C95 | -std=iso9899:199409 | - |
| 1999 | ISO/IEC 9899:1999 | C99 | - | -std=c99, -std=iso9899:1999 | -std=gnu99 |
| 2011 | ISO/IEC 9899:2011 | C11 | - | -std=c11, -std=iso9899:2011 | -std=gnu11 |
| 2018 | ISO/IEC 9899:2018 | C18 | - | -std=c18, -std=iso9899:2018 | -std=gnu18 |
C++版本更迭
| 年份 | C++标准 | 通用名 | 别名 | 标准编译选项 | GNU扩展选项 |
|---|---|---|---|---|---|
| 1978 | C with Classes | - | - | - | - |
| 1998 | ISO/IEC 14882:1998 | C++98 | - | -std=c++98 | -std=gnu++98 |
| 2003 | ISO/IEC 14882:2003 | C++03 | - | -std=c++03 | -std=gnu++03 |
| 2011 | ISO/IEC 14882:2011 | C++11 | C++0x | std=c++11, std=c++0x | std=gnu++11, std=gnu++0x |
| 2014 | ISO/IEC 14882:2014 | C++14 | C++1y | std=c++14, std=c++1y | std=gnu++14, std=gnu++1y |
| 2017 | ISO/IEC 14882:2017 | C++17 | C++1z | std=c++17, std=c++1z | std=gnu++17, std=gnu++1z |
| 2020 | to be determined | C++20 | C++2a | -std=c++2a | std=gnu++2a |
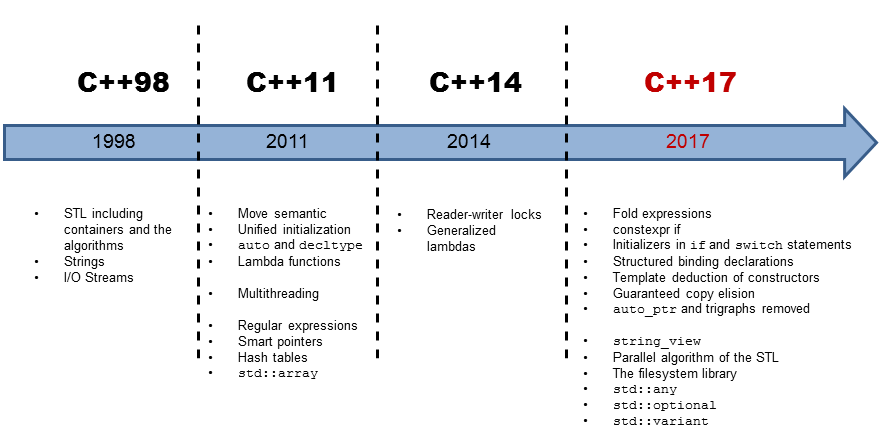

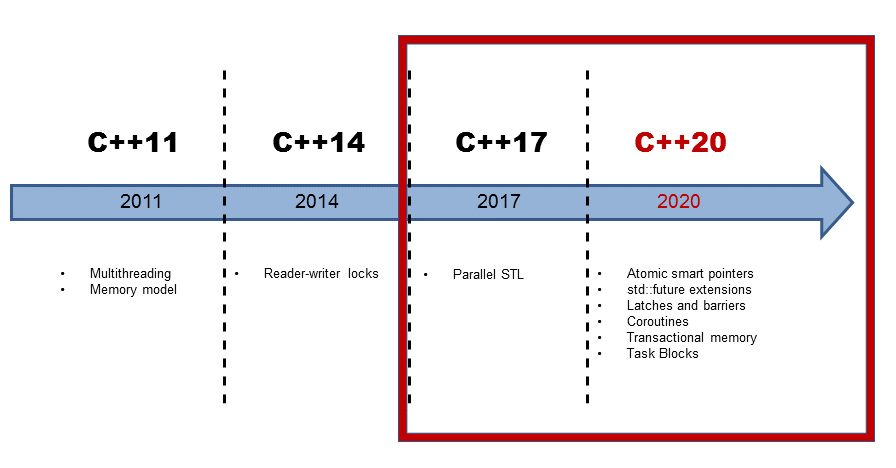
https://cppeurope.com/wp-content/uploads/2019/03/ConcurrencyAndParallelismWith2017and2020.pdf

小结1:多线程编程方案比较
多线程编程是并发编程的基础。对于C++而言,当我们需要使用多线程编程时,必须用到线程库,可以使用下列线程库之一:
1.第三方线程库:如boost::thread库
2.自从C++ 11开始支持的std::thread
3.操作系统相关的线程API,如在Linux上,可以使用pthread库。
除此之外,还可以使用omp来使用多线程。它的好处是跨平台,使用简单。
├── std //
│ ├── C++20 (C++20) //
│ │ ├── Coroutines // 公共组件
│ │ │ ├── alertTip.vue // 弹出框组件
│ │ │ ├── buyCart.vue // 购物车组件
│ │ │ ├── computeTime.vue // 倒计时组件
│ │ │ ├── loading.vue // 页面初始化加载数据的动画组件
│ │ │ ├── mixin.js // 组件混合(包括:指令-下拉加载更多,处理图片地址)
│ │ │ ├── ratingStar.vue // 评论的五颗星组件
│ │ │ └── shoplist.vue // msite和shop页面的餐馆列表公共组件
│ │ ├── Concurrency // 并发(concurrency)
│ │ │ ├── std::jthread // std::jthread基于已经存在的std::thread,
│ │ │ ├── buyCart.vue // 购物车组件
│ │ │ ├── computeTime.vue // 倒计时组件
│ │ │ ├── loading.vue // 页面初始化加载数据的动画组件
│ │ │ ├── mixin.js // 组件混合(包括:指令-下拉加载更多,处理图片地址)
│ │ │ ├── ratingStar.vue // 评论的五颗星组件
│ │ │ └── shoplist.vue // msite和shop页面的餐馆列表公共组件
│ │ ├── footer
│ │ │ └── footGuide.vue // 底部公共组件
│ │ └── header
│ │ └── head.vue // 头部公共组件
│ ├── Algorithm library (C++17) // 对STL库中的69个算法加入了执行策略(execution policies)
│ │ ├── Execution policies // 公共组件
│ │ │ ├── std::execution::par_unseq // Parallel and vectorised=> SIMD
│ │ │ ├── future // 购物车组件
│ │ │ ├── computeTime.vue // 倒计时组件
│ │ │ ├── loading.vue // 页面初始化加载数据的动画组件
│ │ │ ├── mixin.js // 组件混合(包括:指令-下拉加载更多,处理图片地址)
│ │ │ ├── ratingStar.vue // 评论的五颗星组件
│ │ │ └── shoplist.vue // msite和shop页面的餐馆列表公共组件
│ │ ├── thread
│ │ │ └── footGuide.vue // 标准库启动线程的方法可分为三类:async、thread以及packaged_task
│ │ ├── packaged_task
│ │ │ └── footGuide.vue // 标准库启动线程的方法可分为三类:async、thread以及packaged_task
│ │ └── async
│ │ └── head.vue // 标准库启动线程的方法可分为三类:async、thread以及packaged_task
│ ├── std::thread (C++11) // C++11 标准提供了一个新的线程库,跨平台。see:https://changkun.de/modern-cpp/zh-cn/07-thread/index.html
│ │ ├── < thread > //提供线程创建及管理的函数或类接口;
│ │ ├── < condition_variable > //允许一定量的线程等待(可以定时)被另一线程唤醒,然后再继续执行;
│ │ ├── < atomic > : 为细粒度的原子操作(不能被处理器拆分处理的操作)提供组件,允许无锁并发编程
│ │ └── < future > : 提供了一些工具来获取异步任务(即在单独的线程中启动的函数)的返回值,并捕捉其所抛出的异常;
│ ├── (C) //
├── Option: OS Thread library // 与操作系统相关的专用线程库,这些多线程库依赖于具体的平台
│ ├── Linux //
│ │ ├── pthread // Linux‘s Pthread #include<pthread.h>
│ │ │ ├── pthread_create // 类似于Windows _beginthread
│ │ │ └── pthread_exit // 类似于Windows _endthread
│ │ ├── footer
│ │ │ └── footGuide.vue // 底部公共组件
│ │ └── header
│ │ └── head.vue //
│ ├── Windows
│ │ ├── CreateThread // Windows API
│ │ ├── AfxBeginThread // Only for Windows MFC
│ │ ├── _beginthread // #include<process.h>
│ │ └── rem.js // px转换rem
├── Option: Third Thread library //
│ ├── OpenMP // OpenMP是一种用于共享内存系统的多线程程序设计方案。
│ ├── Qpar // see:https://docs.microsoft.com/en-us/cpp/error-messages/tool-errors/vectorizer-and-parallelizer-messages?view=vs-2019
│ ├── PPL // 是微软开发的PPL。并发运行时(cocurrency runtime),数据并行或任务并行的类。并行模式库(PPL)提供了同时对数据集合执行工作的算法。 这些算法来自C++11 threads 标准库提供的算法。但比C++11 threads更好使用.
│ ├── AMP // GPU并行技术:AMP:允许使用现代图形处理器进行通用编程的类,就是GPU并行技术。MS最新的并行技术,代码更改最
│ ├── CUDA // GPU并行技术
│ ├── OpenACC // GPU并行技术
C++
C++标准并没有提供对多进程并发的原生支持,所以C++的多进程并发要靠其他API——这需要依赖相关平台。
可以使用操作系统相关的线程API,如:
在Windows上,
CreateThread是Win32 API函数,AfxBeginThread最终要调到CreateThread
AfxBeginThread是MFC的全局函数,是对CreateThread的封装。
_beginthread()和_beginthreadex()是C运行时库调用,它们在后台调用CreateThread()。
在Linux上,可以使用pthread库。
在linux下类似于_beginthread 和 _endthread 的 是pthread_create和pthread_exit
linux下包含头文件 #include<pthread.h>
C++ standard library detail
Since C++11, the standard library has provided a robust, portable, and increasingly expressive foundation for multithreaded programming.
C++11
C++11 标准提供了一个新的线程库thread,内容包括了管理线程、保护共享数据、线程间的同步操作、低级原子操作等各种类。此库为跨平台线程库。标准极大地提高了程序的可移植性,以前的多线程依赖于具体的平台,而现在有了统一的接口进行实现。不用再用linux下pthread和win32的thread库了,一套代码跨平台.
C++11 新标准中引入了几个头文件来支持多线程编程:(所以我们可以不再使用 CreateThread 来创建线程,简简单单地使用 std::thread 即可。)
C++11 新增了并发编程的线程支持库
Since C++11 C++ faces the requirements of the multicore architectures. The 2011 published standard defines, how a program should behave in the presence of many threads. The multithreading capabilities of C++11 consist of two parts. At on hand, there is the well-defined memory model; at the other hand, there is the standardised threading API.
The standardised threading interface in C++11 consists of the following components.
Threads
Tasks
Thread-local data
Condition variables< thread > : 提供线程创建及管理的函数或类接口;
< mutex > : 为线程提供获得独占式资源访问能力的互斥算法,保证多个线程对共享资源的同步访问;
< condition_variable > : 允许一定量的线程等待(可以定时)被另一线程唤醒,然后再继续执行;
< future > : 提供了一些工具来获取异步任务(即在单独的线程中启动的函数)的返回值,并捕捉其所抛出的异常;
< atomic > : 为细粒度的原子操作(不能被处理器拆分处理的操作)提供组件,允许无锁并发编程With C++11 you can parallelize a for loop with only a few lines of codes. This splits a for loop into smaller chunks and assign each sub loop to a thread:
/// Basically replacing:
void sequential_for(){
for(int i = 0; i < nb_elements; ++i)
computation(i);
}
/// By:
void threaded_for(){
parallel_for(nb_elements, [&](int start, int end){
for(int i = start; i < end; ++i)
computation(i);
} );
}#include <iostream>
#include <thread>
int main() {
std::thread t([](){
std::cout << "hello world." << std::endl;
});
t.join();
return 0;
}PPL
The Microsoft concurrency namespace, provided via #include <ppltasks.h>, is an alternative to C++11 threads. The concurrency namespace functions are at a higher level of abstraction than C++11 threads and are easier to use.
C++17
C++ 17标准中对STL库中的69个算法加入了执行策略(execution policies),允许在少量修改的情形下,对原有STL库算法实现并行计算。它由域名空间algorithm.h来实现。
从C++17开始。<algorithm>和<numeric> 头文件的中的很多算法都添加了一个新的参数:sequenced_policy。
借助这个参数,开发者可以直接使用这些算法的并行版本,不用再自己创建并发系统和划分数据来调度这些算法。
With C++17, the most of the algorithms of the Standard Template Library will be available in a parallel version. Therefore, you can invoke an algorithm with a so-called execution policy. This execution policy specifies if the algorithm runs sequential (std::seq), parallel (std::par), or parallel and vectorised (std::par_unseq).
std::vector<int> vec ={3, 2, 1, 4, 5, 6, 10, 8, 9, 4};
std::sort(vec.begin(), vec.end()); // sequential as ever
std::sort(std::execution::seq, vec.begin(), vec.end()); // sequential
std::sort(std::execution::par, vec.begin(), vec.end()); // parallel
std::sort(std::execution::par_unseq, vec.begin(), vec.end()); // parallel and vectorizedTherefore, the first and second variations of the sort algorithm run sequential, the third parallel, and the fourth parallel and vectorised.
C++ 17标准中一个令人兴奋的特性是对STL库中的69个算法加入了执行策略(execution policies),允许在少量修改的情形下,对原有STL库算法实现并行计算,这对希望提高效率的开发者无疑是一个很大的福音。目前主流 vs 2019 16.8 C++编译器已加入对该特性的支持。
Concurrency and Parallelism in C++17
Parallel Loops in C++17
With the parallel algorithms in C++17 we can now use:
std::vector<std::string> foo;
std::for_each(
std::execution::par_unseq,
foo.begin(),
foo.end(),
[](auto&& item)
{
//do stuff with item
})to compute loops in parallel. The first parameter specifies the execution policy
std::async
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <future>
template <typename RAIter>
int parallel_sum(RAIter beg, RAIter end)
{
auto len = end - beg;
if(len < 1000)
return std::accumulate(beg, end, 0);
RAIter mid = beg + len/2;
auto handle = std::async(std::launch::async,
parallel_sum<RAIter>, mid, end);
int sum = parallel_sum(beg, mid);
return sum + handle.get();
}
int main()
{
std::vector<int> v(10000, 1);
std::cout << "The sum is " << parallel_sum(v.begin(), v.end()) << '\n';
}Concurrent programming, with examples
https://begriffs.com/posts/2020-03-23-concurrent-programming.html
https://en.cppreference.com/w/cpp/algorithm/execution_policy_tag_t
https://devblogs.microsoft.com/cppblog/using-c17-parallel-algorithms-for-better-performance/
C++17 Parallel Algorithms
adjacent_difference
adjacent_find
all_of
any_of
count
count_if
equal
exclusive_scan
find
find_end
find_first_of
find_if
for_each
for_each_n
inclusive_scan
mismatch
none_of
partition
reduce
remove
remove_if
search
search_n
sort
stable_sort
transform
transform_exclusive_scan
transform_inclusive_scan
transform_reduceC++17 Parallel Algorithms
#include <vector>
#include <execution>
#include <algorithm>
int main() {
std::vector<double> data(1000000, 1.0);
std::for_each(std::execution::par, data.begin(), data.end(), [](double &x) {
x = x*2.0;
});
return 0;
}
C++20
C++20 offers totally new multithreading concepts. The key idea is that multithreading becomes a lot simpler and less error-prone.
Atomic smart pointer
The atomic smart pointer std::shared_ptr and std::weak_ptr have a conceptional issue in multithreading programs. They share mutable state. Therefore, they a prone to data races and therefore undefined behaviour. std::shared_ptr and std::weak_ ptr guarantee that the in- or decrementing of the reference counter is an atomic operation and the resource will be deleted exactly once, but both does not guarantee that the access to its resource is atomic. The new atomic smart pointers solve this issue.
std::atomic_shared_ptr
std::atomic_weak_ptr
c++20协程
Visual Studio 2019 version 16.8 Preview 3 comes with a huge collection of updates for C++ 20 programmers
We’ve improved support for major C++20 features across our compiler, standard library, and IDE. You can now use Modules, Concepts, Coroutines, and (some of) Ranges all in the same project!
C++20 Coroutines are now feature-complete and available under /std:c++latest. When using C++20 Coroutines you should include the <coroutine> header. Support for our legacy behaviour is available under <experimental/coroutine> and the /await switch
C++20 Coroutines blogpost.https://devblogs.microsoft.com/cppblog/c-coroutines-in-visual-studio-2019-version-16-8/
coroutine ts正式进入c++20,Coroutine就是函数,只不过是可以suspend和resume的函数,也就是你可以暂停这个函数的执行(实际上就是在suspend的地方直接返回到caller.c++已经进入协程时代.Coroutine, 异步,同步,async, await.
c++的协程功能是给库的开发者使用的,所以看起来比较复杂,但是经过库的作者封装以后用起来是非常简单的,比如说asio里面就已经封装好了
C++ 23
C++23 新增 / 强化的并发能力
std::jthread(C++20,C++23 完善)
自动 join
原生支持 std::stop_token
已被认为是 现代线程首选
VS 支持:100%(VS 2022)
C++26
标准异步任务模型:Executors + async task 组合(then/when_all)
Execution control library
https://en.cppreference.com/w/cpp/experimental/execution.html
工具分类
按功能来分有这些:
资源的访问——C++11标准提供了一些基本的同步原语atomic、mutex、lock、condition_variable;
任务的封装——C++11标准提供了几种任务封装形式future、promise、packaged_task;
并行版算法——C++17标准提供了常用算法的并行版本;
任务的结构——在C++20里将补全任务结构控制,包括then、 when_all、 when_any这三个用来关联多个future的函数。
任务的执行——现有的任务执行者基本都是线程池,每个线程不断的尝试获取一个任务并执行,类似于一个while循环。此外,在C++20/23中有executor的提案;
任务的调度——这部分负责了任务的投递和分发,他在多线程之间维持了一个任务容器集合,提供的接口主要包括接受新任务、取出一个任务和判断容器是否为空,最常见的是concurrenct_queue。这部分标准库并没有提供,有多种不同的实现方式。
C++ 标准版本历史 以及 Visual Studio 2022 / 2026 对各版本的支持情况
2.vs 2019编译器 对c++11 到 c++20的支持情况查询(C++ compiler support)
Microsoft C++17 c++20 Visual Studio 20** language conformance table
https://docs.microsoft.com/en-us/cpp/overview/visual-cpp-language-conformance?view=vs-2019
3.vs 2022 编译器 对c++11 到 c++23的支持情况查询(C++ compiler support)
https://en.cppreference.com/w/cpp/compiler_support
Added compiler support for C++23 feature deducing this, available under the /std:c++latest flag.
4.vs 2026 编译器 对c++11 到 c++26的支持情况查询(C++ compiler support)
Visual Studio 2026 version 18.0 ships with the v145 platform toolset for MSBuild C++ projects and Microsoft C++ (MSVC) Build Tools version 14.50, which offers the best conformance, build performance, and runtime performance story yet. To access all the new language features, build with /std:c++latest. Or, if you want to be restricted to features up to C++23, use /std:c++23preview.
https://learn.microsoft.com/en-us/cpp/overview/what-s-new-for-msvc?view=msvc-180
vs 2026 编译器 - MSVC Build Tools 14.51
https://github.com/microsoft/STL/wiki/Changelog#msvc-build-tools-1450
20260112
MSVC Build Tools v14.30-v14.43 are now available in Visual Studio 2026
https://learn.microsoft.com/en-us/visualstudio/releases/2026/release-notes#18.2.0
3.并发编程
并发系统从硬件组网结构上可分为两大类:
共享内存系统:单台计算机,各个核可以共享访问计算机的内存。
分布式内存系统:多台计算机,每个核都有自己独立私有的内存,核之间的通信需要通过网络发送消息。

OpenMP是一种用于共享内存系统的多线程程序设计方案。
并行优化代码的基本方法
优化可分为异步框架;任务并行;数据并行
从大到小一共可以分成三级:
1.异步框架;
2.任务并行;
3.数据并行。
在实际工作中,一般是:
Step 1:先设计异步框架,包括异步处理任务以及异步任务的异构化等;
Step 2:一般是做数据并行优化(SIMD),利用CPU的向量指令来对多条数据并行处理;
这两步是代码优化的重心,一般做完这两步,系统性能会有明显的提升。
Step 3:for循环的并行优化。与前两者不同的是,for循环往往是处理同一类任务,且通常会涉及到对同一个变量的读写,所以异步是不能用。
并行(parallelism)与并发(concurrency)
并发是逻辑上的同时发生(concurrency),而并行(parallelism)是物理上的同时发生.
同一线程即可以在同一个处理器上并发运行,也可以在多个处理器上并行运行。
单核CPU处理系统只有并发,没有并行,它可以支持多个任务的运行,但是因为只有一个处理器,所以无法并行;
多核CPU处理器可以支持并行和并发,多个核可同时并行处理任务,而单核上也可以并发处理多个线程。
C++多线程与CPU多核多线程的关系
程序的多线程和CPU的多线程并不直接关联,底层的任务调度、线程调度都是操作系统来实现的。你只能告诉操作系统,这些工作是并行的,还是串行的,至于cpu怎么执行的,由于操作系统的线程调度,最终会把线程分配到每个核心上运行。
线程是一切并发编程的基础,使用时需要包含 线程库 头文件, 它提供了很多基本的线程操作。
例如:std::thread 用于创建一个执行的线程, get_id() 来获取所创建线程的线程 ID,使用 join() 来加入一个线程等等。
开一个死循环线程,线程里不要Sleep,目的就是让CPU满负荷跑,用SetThreadAffinityMask指定线程分别在不同的CPU上跑,从任务管理器中看CPU的负荷,你就知道线程跑在哪个CPU上。
我的电脑上时双CPU。
我在InitInstance中用:
bresult = SetProcessAffinityMask( GetCurrentProcess() , 3 ) ;
DWORD dwCPUid = SetThreadAffinityMask( GetCurrentThread() , 1 ) ;
在另一个线程中使用
DWORD dwCPUid = SetThreadAffinityMask( GetCurrentThread() , 2 ) ;
但 两个线程还是一直CPU0上运行。POSIX Threads (Linux‘s Pthreads)
POSIX Threads (Pthreads for short) is a standard for programming with threads, and defines a set of C types, functions and constants.
More generally, threads are a way that a program can spawn concurrent units of processing that can then be delegated by the operating system to multiple processing cores. Clearly the advantage of a multithreaded program (one that uses multiple threads that are assigned to multiple processing cores) is that you can achieve big speedups, as all cores of your CPU (and all CPUs if you have more than one) are used at the same time.
Here is a simple example program that spawns 5 threads, where each one runs the myFun() function:
OS:Linux
Thread Liabray:pthread.h which only for Linux
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NTHREADS 5
void *myFun(void *x)
{
int tid;
tid = *((int *) x);
printf("Hi from thread %d!\n", tid);
return NULL;
}
int main(int argc, char *argv[])
{
pthread_t threads[NTHREADS];
int thread_args[NTHREADS];
int rc, i;
/* spawn the threads */
for (i=0; i<NTHREADS; ++i)
{
thread_args[i] = i;
printf("spawning thread %d\n", i);
rc = pthread_create(&threads[i], NULL, myFun, (void *) &thread_args[i]);
}
/* wait for threads to finish */
for (i=0; i<NTHREADS; ++i) {
rc = pthread_join(threads[i], NULL);
}
return 1;
}output:
plg@wildebeest:~/Desktop$ gcc -o go go.c -lpthread
plg@wildebeest:~/Desktop$ ./go
spawning thread 0
spawning thread 1
Hi from thread 0!
spawning thread 2
Hi from thread 1!
spawning thread 3
Hi from thread 2!
spawning thread 4
Hi from thread 3!
Hi from thread 4!
OpenMP的三种线程与核绑定方式
https://blog.csdn.net/weixin_38180944/article/details/87919498
Visual Studio c++使用并行模式库PPL、C++ AMP、OpenMP 以及与 Windows 多线程相关的其他功能
使用多线程技术:对于C++而言,当我们需要使用多线程时,可以使用第三方线程库boost::thread库或者自从C++ 11开始支持的std::thread,也可以使用操作系统相关的线程API,如在Linux上,可以使用pthread库。
MPI
If you want to run your program on N nodes (not necessarily 2) you can use MPI:www.mpich.org
It depends on the programming environment and the operating system. If you want to use several computers in a network you can use MPI. On a single computer you can use OpenMP (a good tutorial here: http://bisqwit.iki.fi/story/howto/openmp/ ).
There are also other tools like the one here: http://mpc.hpcframework.paratools.com/ that allows you to run parallel programs on clusters of multiprocessor/multicore NUMA nodes.
Note that with MPI you can run N threads also on a single machine, for instance it could run a program in parallel on 8 cores of a single machine。
MPI实现并行是进程级;采用的是分布式内存系统,显式(数据分配方式)实现并行执行,通过通信在进程之间进行消息传递,可扩展性好。MPI虽适合于各种机器,但它的编程模型复杂。
Qpar:自动并行化,加速代码执行的编译器优化。个人感觉最无脑的并行技术,对代码更改最小
AMP:允许使用现代图形处理器进行通用编程的类,就是GPU并行技术。MS最新的并行技术,代码更改最大
C++ AMP实战:绘制曼德勃罗特集图像 https://www.cnblogs.com/Ninputer/archive/2012/01/03/2310945.html
C++ AMP:在GPU上做并行计算
https://www.cnblogs.com/allenlooplee/archive/2012/08/15/2640644.html
CUDA
GPU computing
OpenACC
GPU computing
c++并行计算库TBB:是intel开发的TBB,
c++并行计算库PPL:是微软开发的PPL。并发运行时(cocurrency runtime),数据并行或任务并行的类。并行模式库(PPL)提供了同时对数据集合执行工作的算法。 这些算法来自C++11 threads 标准库提供的算法。但比C++11 threads更好使用.
The Microsoft concurrency namespace, provided via #include <ppltasks.h>, is an alternative to C++11 threads. The concurrency namespace functions are at a higher level of abstraction than C++11 threads and are easier to use.
Windows *线程,
英特尔®线程构建模块进行并行编程
与操作系统无关的线程API( c + + 标准库提供),
(1)从C++ 11开始支持的std::thread
4.专门为操作系统开发的库
与操作系统相关的线程API,
(1)在Linux上,可以使用pthread库。
(2)在Windows上,
CreateThread是Win32 API函数,AfxBeginThread最终要调到CreateThread
AfxBeginThread是MFC的全局函数,是对CreateThread的封装。
。
OpenMP
OpenMP boils down to "marking" some parts of your program as parallizable, and it does much of the job automatically.
The complete picture is this: you would use MPI to send/receive messages between nodes, then each node implements OpenMP to manage the 4 or 8 or 16 threads for the physical cores of the single node.
OpenMP是线程级(并行粒度);采用的是共享内存系统,隐式(数据分配方式)实现并行执行;可扩展性差;正因为采用共享内存分布系统,意味着它只适应于SMP(Symmetric Multi-Processing 对称多处理结构),DSM(Distributed Shared Memory 共享内存分布系统)机器,不适合于集群。OpenMP API的Microsoft实现。经典的外部并行技术库,很多科学计算都用这个,跨语言和平台。
OpenMP official websit: https://www.openmp.org
latest version:OpenMP 5.1 updated 20210826
OpenMP API 6.0 Specification – Nov 2024; updated 202512
1.Microsoft Visual Studio has supported the OpenMP 2.0 standard since 2005.
2.Starting in Visual Studio 2019 version 16.9,we added the -openmp:experimental switch to enable minimal support for the OpenMP SIMD directive first introduced in the OpenMP 4.0 standard.openmp 版本历史 及Visual Studio 官方编译器vs 2022 vs 2026的支持情况
MSVC(Visual Studio 官方编译器),只支持 OpenMP 2.0。
微软已明确:不会在 MSVC 中继续推进 OpenMP 4/5 的完整实现
原因:
微软主推:
C++20 协程
PPL / Concurrency Runtime
C++ 标准并发
OpenMP 在 Windows 生态:不是战略方向
GPU / accelerator 被 CUDA / DirectML / D3D12 接管
OpenMP 版本历史
| OpenMP 版本 | 年份 | 关键特性 |
| --------- | ---- | ------------------------------------------------------ |
| **2.0** | 2002 | `#pragma omp parallel for`(经典 for 并行) |
| **2.5** | 2005 | C++ 支持改进 |
| **3.0** | 2008 | **task / taskwait**(任务模型起点) |
| **3.1** | 2011 | 小修订 |
| **4.0** | 2013 | **target / SIMD / accelerator** |
| **4.5** | 2015 | target 数据映射完善 |
| **5.0** | 2018 | **task depend / memory model / unified shared memory** |
| **5.1** | 2020 | 互操作(interop) |
| **5.2** | 2021 | 设备 & 任务增强 |
| **6.0** | 2024 | **与 C++ 并发 / 异构模型进一步融合** |
How to use
OpenMP in Visual C++ 2019
/openmp (Enable OpenMP 2.0 Support)
How to Enable OpenMP in Visual C++ 2019
Open the project's Property Pages dialog box. For details, see Set C++ compiler and build properties in Visual Studio.
Expand the Configuration Properties > C/C++ > Language property page.
Modify the OpenMP Support property.For example
src/Client/StkUI/StkUI_vc90.vcxproj
<ClCompile>
+ <OpenMPSupport>true</OpenMPSupport>
</ClCompile>see:https://docs.microsoft.com/en-us/cpp/build/reference/openmp-enable-openmp-2-0-support?view=msvc-160
https://learn.microsoft.com/en-us/cpp/parallel/openmp/reference/openmp-clauses?view=msvc-180
In the initial release of Visual Studio 2019 we added the -openmp:experimental switch to enable minimal support for the OpenMP SIMD directive first introduced in the OpenMP 4.0 standard.
see:
Improved OpenMP Support for C++ in Visual Studio 2019
https://devblogs.microsoft.com/cppblog/improved-openmp-support-for-cpp-in-visual-studio/
SIMD Extension to C++ OpenMP in Visual Studio 2019
https://devblogs.microsoft.com/cppblog/simd-extension-to-c-openmp-in-visual-studio/
32 OpenMP Traps For C++ Developers https://www.viva64.com/en/a/0054/
OpenMP in Visual C++ https://docs.microsoft.com/en-us/cpp/parallel/openmp/openmp-in-visual-cpp?view=vs-2019
OpenMP in Visual C++ https://docs.microsoft.com/en-us/cpp/parallel/openmp/openmp-in-visual-cpp?view=vs-2026
https://learn.microsoft.com/en-us/cpp/parallel/openmp/reference/openmp-clauses?view=msvc-180
并行库-OpenMP
openMP支持的编程语言包括C语言、C++和Fortran,支持OpenMP的编译器包括Sun Studio,Intel Compiler,Microsoft Visual Studio,GCC.
我们公司的游戏编辑器在一些需要处理大量顶点数据的场合使用了OpenMP,选择OpenMP的原因是足够简单,只要添加一条pragma,不需要修改原有代码,并且性能也够用。
我想将一个数组分块,每个处理器处理几行,那应该如何设定让某个处理器处理几行呢?这个编译指导语句应该如何写?
原理很简单,如果用parallel for的话,OMP 运行库自动生成的线程,在每个处理器/核上运行的程序代码是完全一样的, 区别只是在于原先的数组会根据下标变量分成几块,然后分配到不同的处理器/核上运行。就是拆成了几个线程,然后使用事件对象等待所有线程结束,没有做同步,要想更好的控制建议自己写多线程或者线程池什么的。但它的优势是几乎不用改原来的代码
至于如何CPU分配,缺省是平均分配,两个核就二分,四个核就各自按照顺序拿四分之一。 如果出现不同核负载不均衡,计算量不均的现象,可以考虑采用动态的分配方式 .
parallel for 共有四种调度方式
static - Iterations are divided into chunks of size chunk_size, and
the chunks are assigned to the threads in the team in a
round-robin fashion in the order of the thread number.
dynamic - Each thread executes a chunk of iterations, then requests
another chunk, until no chunks remain to be distributed.
guided - Each thread executes a chunk of iterations, then requests
another chunk, until no chunks remain to be assigned.
The chunk sizes start large and shrink to the indicated
chunk_size as chunks are scheduled.
auto - The decision regarding scheduling is delegated to the
compiler and/or runtime system.OpenMP在实际应用中还是很多的,重点是比较简单,如果你的任务之间是完全无依赖,那就一句OpenMP引语就搞定了,相比其他的TBB/Pthread 实在简单太多,而且现代编译器都内置支持,标准也在一直进化。
Visual Studio 2019(16.1.5)为止,还不支持openmp3.0以后的特性.
step 1:Vs 2019 OpenMP环境配置
以Vs 2019作为IDE,C++作为开发语言,在正式进行OpenMP编码之前,需要对编译器稍微配置一下.
设置并行编译选项
建立工程后,点击 菜单栏->Project->Properties,弹出菜单里,点击 Configuration Properties->C/C++->Language->OpenMP Support,在下拉菜单里选择Yes。
//项目-属性- C/C++ - 语言 - OpenMP支持(是)step 2:将for 循环拆分成多个线程
//项目-属性- C/C++ - 语言 - OpenMP支持(是)
#include <omp.h>
...
#pragma omp parallel for
for(int i = 0; i < 10; i++)
{
//dosome;
}
Step 3:在for循环内对需要修改的共享变量进行原子操作
#pragma omp atomic
对变量进行原子操作
size_t count = 0;
int size = static_cast<int>(a.size());
#pragma omp parallel for
for (int i = 0; i < size; ++i)
{
if (is_prime(a[i])) {
#pragma omp atomic
++count;
}
}Step 4:在循环内对需要修改的变量加锁,修改后解除锁
//come from:https://www.iaspnetcore.com/blog/5f8edd14f3819901ee460109/realizing-data-synchronization-and-mutual-exclusion-between-process-and-thread-by-c-
//进入临界区
g_mutexCommPacket.Lock();
m_container.Add(info);
m_datebegin.Add(info.m_dateHistoryReport);
m_dateend.Add(info.m_dateHistoryReport);
m_resultinfo.Add(_T("尾盘急拉"));
//离开临界区
g_mutexCommPacket.Unlock();Step 5:利用PostMessage消息发送给主线程来更新UI
OpenMP的三种线程与核绑定方式(Controlling OpenMP Thread Affinity)
https://blog.csdn.net/weixin_38180944/article/details/87919498
Parallel Loop SIMD Construct
From OpenMP 4.5 Specification:
The parallel loop SIMD construct is a shortcut for specifying a parallel construct containing one loop SIMD construct and no other statement.
The syntax of the parallel loop SIMD construct is as follows:
#pragma omp parallel for simdYou can also write:
#pragma omp parallel
{
#pragma omp for simd
for ...
}
Parallel Programming in Visual C++
Visual C++ provides the following technologies to help you create multi-threaded and parallel programs that take advantage of multiple cores and use the GPU for general purpose programming.
Auto-Parallelization and Auto-Vectorization
Concurrency Runtime
小结2:Visual Studio C++并行编程方案C++版本比较

Note
1.Intel 酷睿 i5-10400 的 GPU(例如 UHD Graphics)主要用于图形显示,虽然可以进行一些 GPU 计算(例如 DirectCompute/OpenCL),但它不是专门的高性能并行加速设备,因此 不能直接通过 C++ / C# 并行库来“自动利用”它进行通用 GPU 计算。
2.独立 GPU(如 NVIDIA CUDA / AMD ROCm 等)真正提供大规模并行计算能力,适合:
大规模矩阵运算、深度学习训练/推理
科学计算、图像处理、大数据计算
需要使用专门的 GPU 计算 API(如 OpenCL、DirectCompute、CUDA(NVIDIA)等)
3.TPU / AI 加速器 主要针对深度学习加速,需要特定框架支持(TensorFlow、ONNX 等)。
4. CPU 并行 适合通用算法、多线程并行 ;而 GPU/TPU 适合高度数据并行(SIMD/SIMT 模式)的大规模任务。普通 C++/C# 并行库不会自动将任务转移到 GPU。
useful links
https://learn.microsoft.com/en-us/cpp/parallel/parallel-programming-in-visual-cpp?view=msvc-180
Taskflow helps you quickly write parallel tasks programs in modern C++
https://github.com/taskflow/taskflow
c++11教程
https://changkun.de/modern-cpp/zh-cn/07-thread/index.html
PPL
C++ 中的并行编程
https://docs.microsoft.com/zh-cn/cpp/parallel/parallel-programming-in-visual-cpp?view=vs-2019
OpenMP
OpenMP Clauses
https://docs.microsoft.com/en-us/cpp/parallel/openmp/reference/openmp-clauses?view=vs-2019
OpenMP
Guide into OpenMP 4.5: Easy multithreading programming for C++
https://www.cnblogs.com/mfryf/p/12744547.html
32 OpenMP Traps For C++ Developers
https://www.viva64.com/en/a/0054/
OpenMP in Visual C++
https://docs.microsoft.com/en-us/cpp/parallel/openmp/openmp-in-visual-cpp?view=vs-2019
openMP的一点使用经验
https://www.cnblogs.com/yangyangcv/archive/2012/03/23/2413335.html
并行计算,基于vs c++ OpenMP的并行编程
https://www.cnblogs.com/hantan2008/p/5961312.html
五种主要多核并行编程库分析与比较
https://blog.csdn.net/weixin_34344677/article/details/94054926
C/C++框架和库
https://cloud.tencent.com/developer/article/1416856
Concurrency and Parallelism with C++17 and C++20/23
https://cppeurope.com/wp-content/uploads/2019/03/ConcurrencyAndParallelismWith2017and2020.pdf
How can I run a parallel programming over 2 or more CPUs , where each CPU have 8 cores?
SIMD Extension to C++ OpenMP in Visual Studio
C++ 实用网站