Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.
除了搜索之外,结合Kibana、Logstash、Beats还被广泛运用在大数据*实时分析领域,包括日志分析、指标监控、信息安全等多个领域。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,甚至通过使用机器学习技术,自动识别异常状况。
ELK
是三款软件的简称,分别是Elasticsearch、Logstash、Kibana组成。

Elastic Stack
在发展的过程中,又有新成员Beats的加入,所以就形成了Elastic Stack。所以说,ELK是旧的称呼,Elastic Stack是新的名字。
Beats并不是指单一的某个技术,它是指一系列技术在总称,采集能力更加轻量级更加强大,并且已经逐渐取代Logstash的地位。
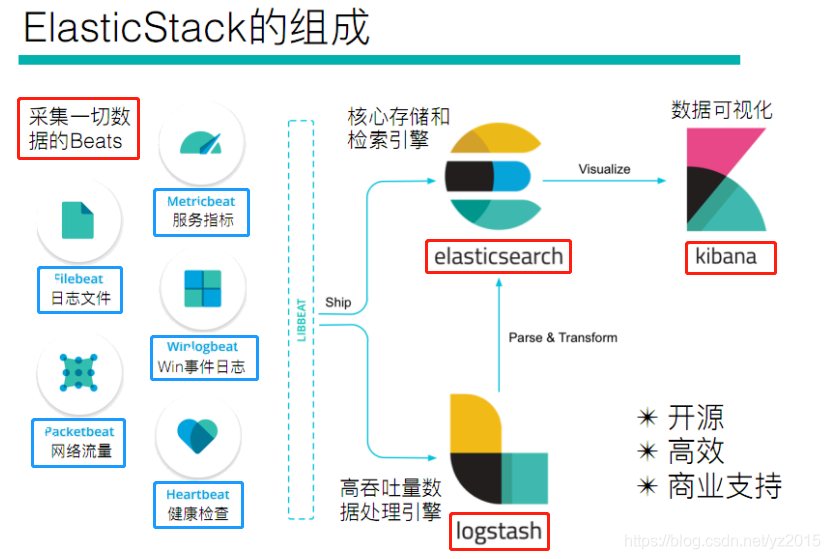
当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据
ElasticSearch是基于lucene的开源搜索引擎,它的查询语法关键字跟lucene一样,如下:
分页:from/size
字段:fields
排序:sort
查询:query
过滤:filter
高亮:highlight
统计:facet
查询:query
对于每个查询项,我们可以通过must、should、mustNot方法对QueryBuilder进行组合,形成多条件查询。(must=>and,should=>or)
Lucene支持基于词条的TermQuery、RangeQuery、PrefixQuery、BolleanQuery、PhraseQuery、WildcardQuery、FuzzyQuery
1.TermQuery与QueryParser
单个单词作为查询表达式时,它相当于一个单独的项。如果表达式是由单个单词构成,QueryParser的parse()方法会返回一个TermQuery对象。
如查询表达式为:content:hello,QueryParser会返回一个域为content,值为hello的TermQuery。
Query query = new TermQuery(“content”, “hello”).
2.RangeQuery与QueryParser
QueryParse可以使用[起始TO 终止]或{起始TO 终止}表达式来构造RangeQuery。
如查询表达式为:time:[20101010 TO 20101210] ,QueryParser会返回一个域为time,下限为20101010,上限为20101210的RangeQuery。
Term t1 = new Term(“time”, “20101010”);
Term t2 = new Term(“time”, “20101210”);
Query query = new RangeQuery(t1, t2, true);
3.PrefixQuery与QueryParser
当查询表达式中短语以星号(*)结尾时,QueryParser会创建一个PrefixQuery对象。
如查询表达式为:content:luc*,则QueryParser会返回一个域为content,值为luc的PrefixQuery.
Query query = new PrefixQuery(luc);
4.BooleanQuery与QueryParser
当查询表达式中包含多个项时,QueryParser可以方便的构建BooleanQuery。QueryParser使用圆括号分组,通过-,+,AND, OR及NOT来指定所生成的Boolean Query。
5.PhraseQuery与QueryParser
在QueryParser的分析表达式中双引号的若干项会被转换为一个PhraseQuery对象,默认情况下,Slop因子为0,可以在表达式中通过~n来指定slop因子的值。
如查询表达式为content:“hello world”~3,则QueryParser会返回一个域为content,内容为“hello world”,slop为3的短语查询。
Query query = new PhraseQuery();
query.setSlop(3);
query.add(new Term(“content”, “hello”);
query.add(new Term(“content”, “world”);
6. Wildcard与QueryParser
Lucene使用两个标准的通配符号,*代表0或多个字母,?代表0或1个字母。但查询表达式中包含*或?时,则QueryParser会返回一个WildcardQuery对象。但要注意的是,当*出现在查询表达式的末尾时,会被优化为PrefixQuery;并且查询表达式的首个字符不能是通配符,防止用户输入以通配符*为前缀的搜索表达式,导致lucene枚举所有的项而耗费巨大的资源。
6.FuzzyQuery和QueryParser
QueryParser通过在某个项之后添加“~”来支持FuzzyQuery类的模糊查询。